在現有專案,使用 Github Spec Git
Using GitHub Spec Kit with your EXISTING PROJECTS
前言:在現有專案中使用 SpecKit
今天要解決社群最大的需求之一:如何在現有專案中使用 SpecKit?我將用自己的部落格作為實際案例,這是一個已經維護近十年的專案。
專案背景
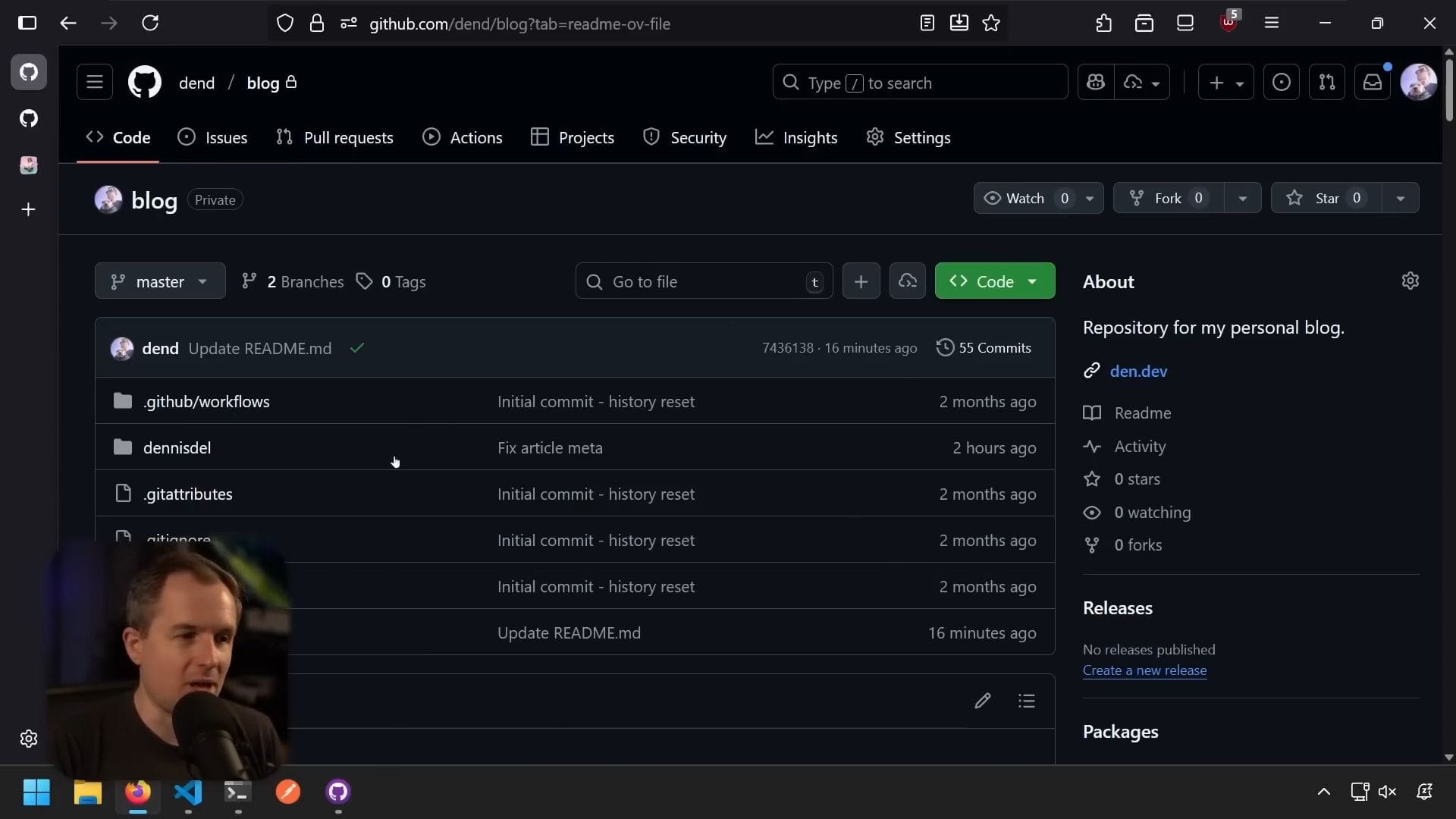
我的部落格是用 Hugo 建立的靜態網站,沒有使用任何其他框架。它使用 Tailwind CSS 進行樣式設計,並採用了 Congo mod 主題的修改版本。整個網站的設計我非常滿意,包括自訂的介紹、細節和完全客製化的存檔頁面。
新需求:建立閱讀清單
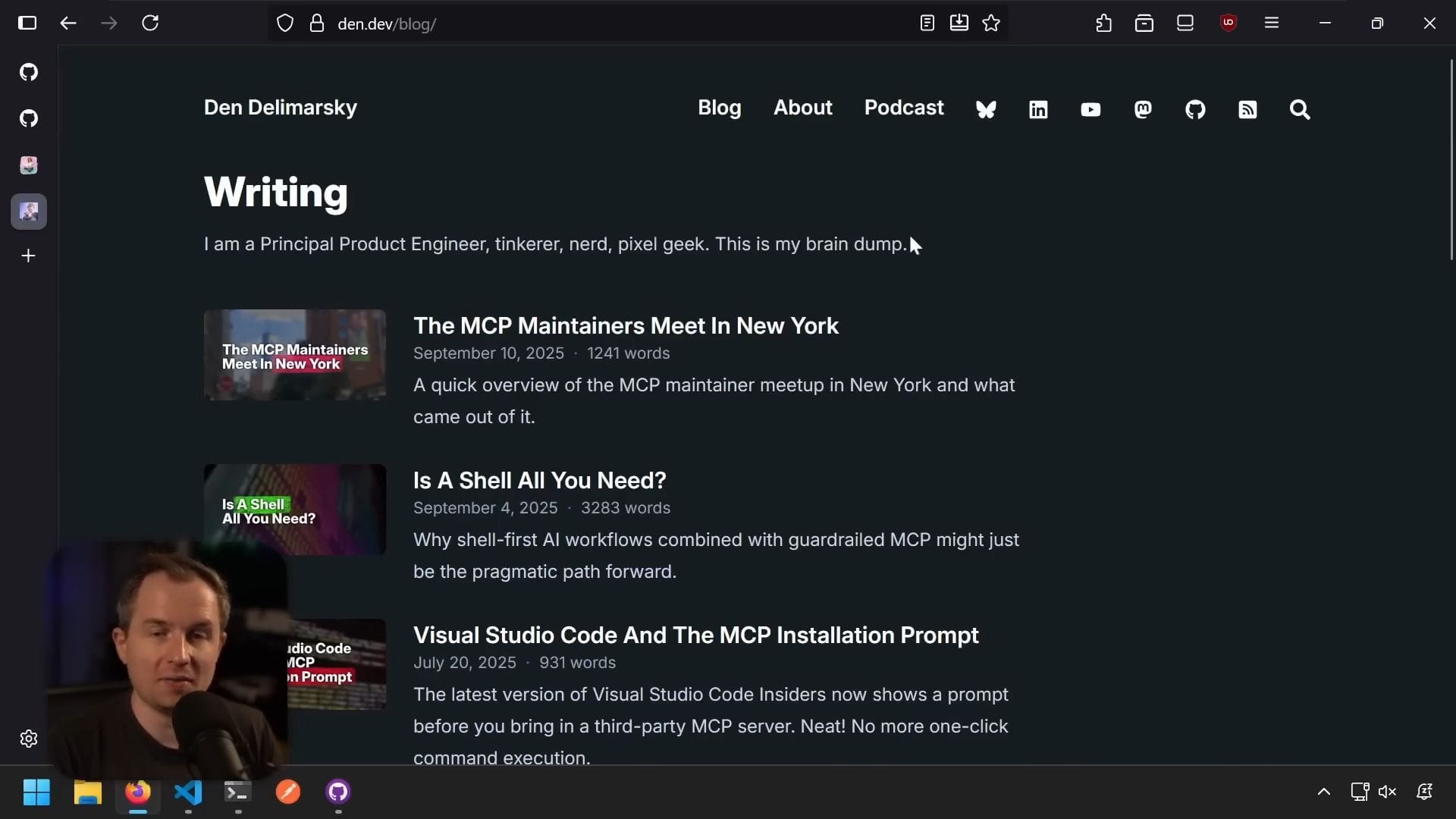
我想在網站上加入閱讀清單功能。我是個熱愛閱讀的人,希望能追蹤並展示我讀過的書籍。這個靈感來自 Molly White 的書單頁面(mollywhite.net),她在頁面上記錄了所有正在閱讀的書籍。
開始使用 SpecKit
專案結構檢視
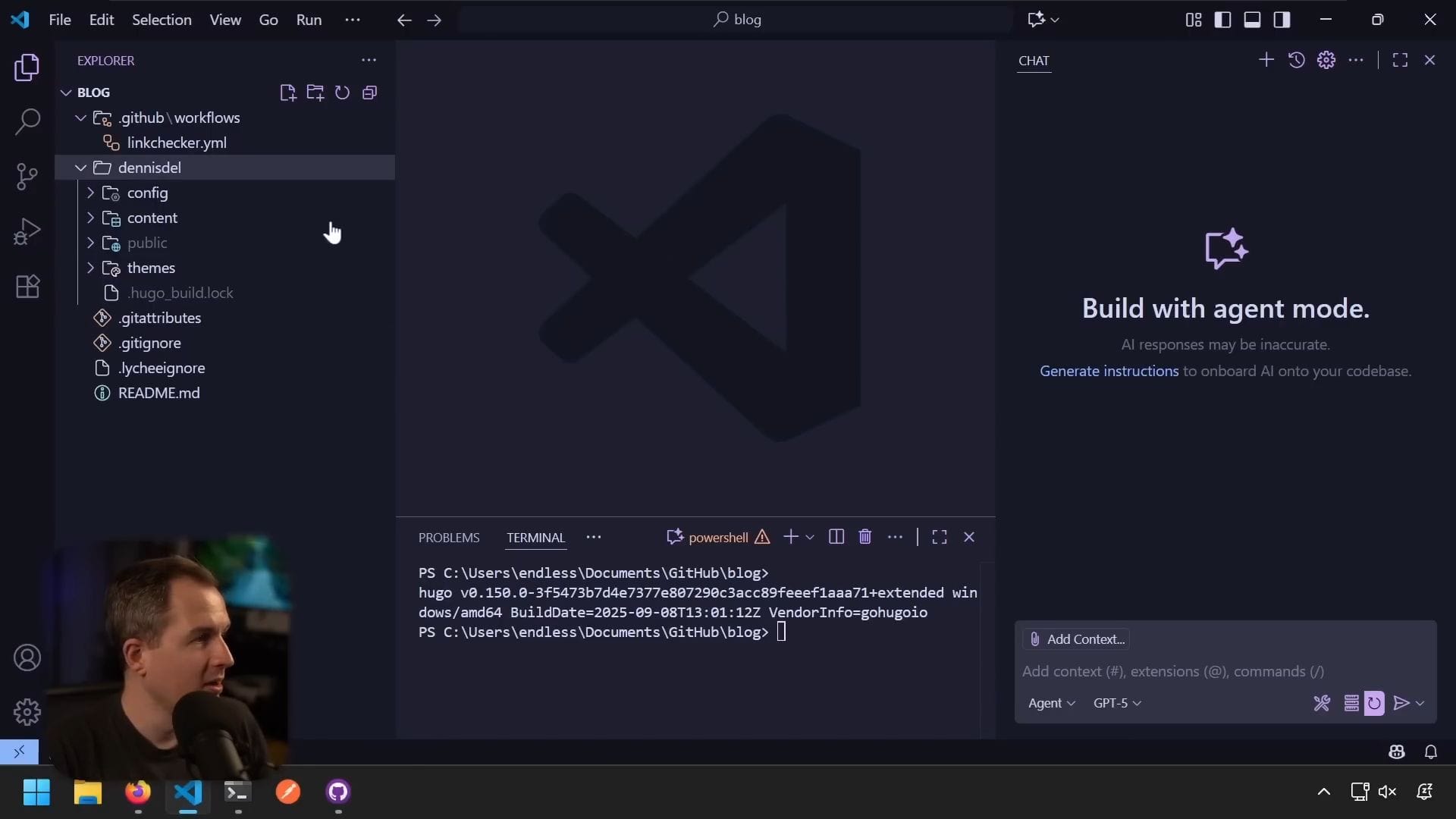
讓我們先看看專案結構。這是典型的 Hugo 網站內容:
- 設定檔:標準的 TOML 格式
- 內容資料夾:包含所有的索引頁面和部落格文章,都是 markdown 檔案
- 主題資料夾:存放修改過的 Congo mod 主題
- package.json:因為這是 Node 管理的主題
這個專案包含許多自訂的佈局、短代碼和局部模板,需要清楚知道每個檔案的位置和如何修改。
初始化 SpecKit
我將使用 SpecKit CLI 的 here 指令,直接在專案資料夾中初始化,不需要指定專案名稱。執行後會出現警告,表示會覆寫現有檔案。
specify here選擇使用 Copilot 搭配 PowerShell,完成後會看到熟悉的斜線指令:
- /constitution
- /specify
- /clarify
- /plan
- /task
- /analyze
- /implement
檢查新增的檔案
SpecKit 加入了以下內容:
.github資料夾:原有的 GitHub Actions 工作流程prompts資料夾:新增的提示specify資料夾:包含 memory、scripts 和 templates
定義專案憲章
選擇模型
我選擇使用 Claude Sonnet 4 進行大部分的寫程式工作。不過根據不同情境,你可能想嘗試不同的模型:
- GPT-5
- Gemini 2.5
- 本地模型(如 Llama)
實驗不同模型很有幫助,因為輸出結果會有差異。有些模型可能過於積極,有些則較為謹慎,會等待你的輸入來釐清細節。
撰寫憲章內容
這是一個靜態網站
完全不使用任何框架
使用 Hugo 建立
主題位於 themes 資料夾
所有樣式都使用該主題
即使新增樣式也一樣
絕對不要有任何額外的相依套件
不需要 package.json 或其他主題或元件重點是保持網站原樣,不重新架構整個專案。這是現有專案,運作良好,我喜歡現在的狀態,要保持這樣。
檢查憲章輸出
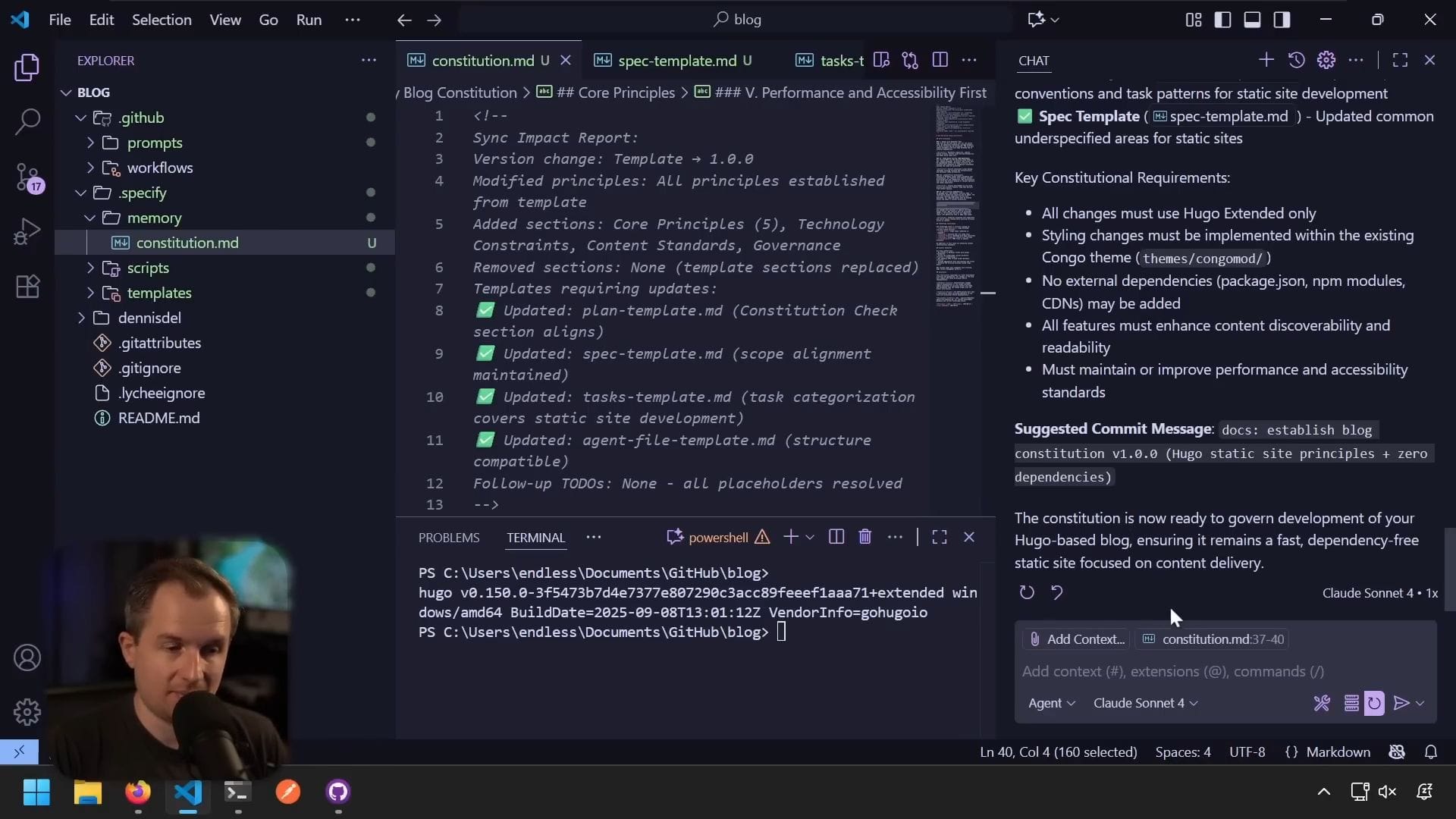
生成的憲章包含:
核心約束:
- 僅使用靜態網站生成器
- Hugo 必須是唯一的建立工具
- 基於主題的樣式
- 內容優先
- 零外部相依套件
- 效能和可訪問性優先
內容標準:
- 語意化 HTML
- 完整的中繼資料
- 分類系統
- 治理規範
這些約束對專案來說都很合理。憲章適用於整個專案,不只是單一功能或錯誤修復。
定義功能規格
使用 /specify 指令
在這個階段,要非常具體地描述你想做什麼。讓我先展示網站可以正常建立:
cd dennisdel
hugo server -D網站在 localhost:1313 上執行,所有內容都在本機上運作。
撰寫規格
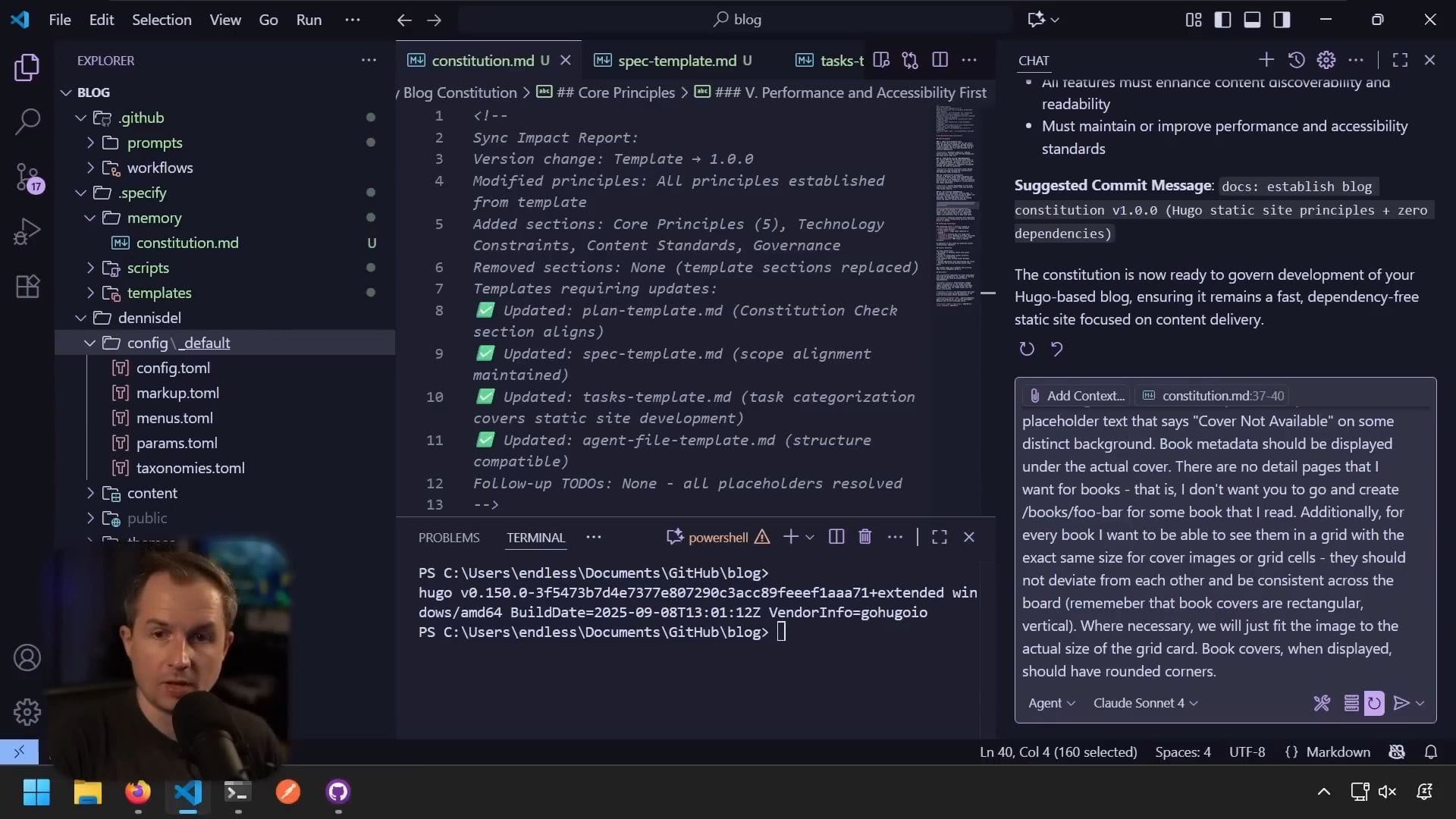
我會明確定義書籍頁面的具體需求:
建立閱讀清單頁面
使用 /books 路由
資料從 config 資料夾的 TOML 檔案填入
類似其他 TOML 檔案注意這些看起來像是需要知道自己在做什麼的約束。我確實知道如何維護網站上的書籍資料。 我不是憑感覺寫程式,我對基礎設施、工具和現有內容有固有的了解,我希望它們以特定方式運作,而我使用 AI 來引導它朝那個方向前進。這就是超能力。
知識的重要性
這並不是否定知識的需求。有人認為 AI 會完全消除對工程知識的需求,這不是真的。你仍然需要知道自己在做什麼。憑感覺寫程式不會導致安全漏洞,這是肯定的。
規格的焦點
我也在定義「是什麼」和「為什麼」。記住,specify 指令是關於定義規格,這些是需求。我們還不一定要關注技術堆疊,也不是在這個階段需要定義的部分。我們只是在定義體驗。
執行規格命令
執行後會建立新的分支,因為當我們建立新功能時,會為我們設定好。新的 specs 資料夾包含分支名稱(雖然我不喜歡 001 這個命名,打算改進它)。
現在我們在一個新的隔離環境中運作,不會影響主部落格。我可以安全地提交並查看它如何在線上或本機渲染,而不會因為某處的模板檔案出錯而破壞核心網站。
檢視生成的規格
使用者情境
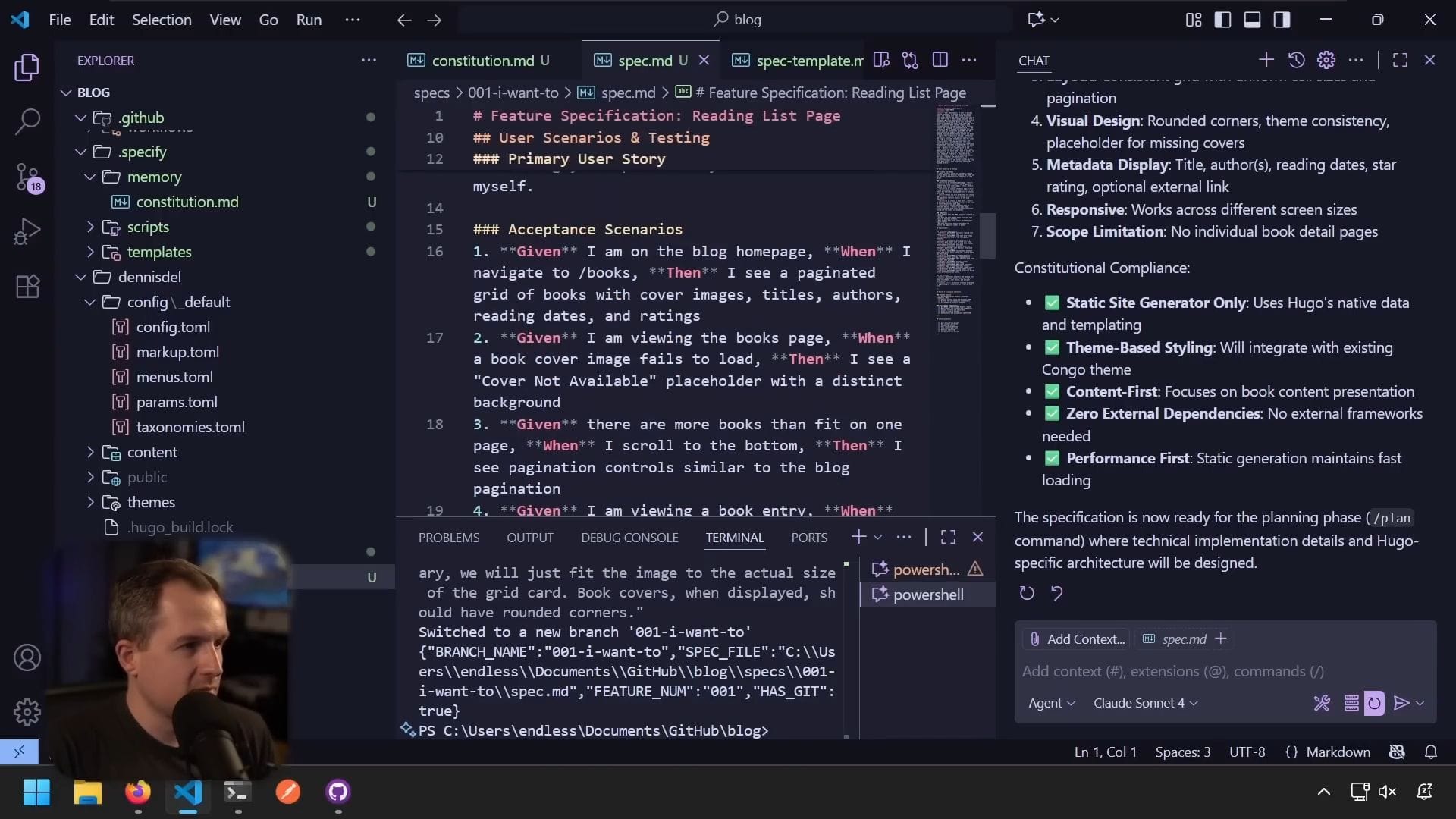
規格包含了使用者情境:
- 當我在部落格首頁導航到 books 時
- 會看到書籍網格,包含封面圖片、標題等
功能需求
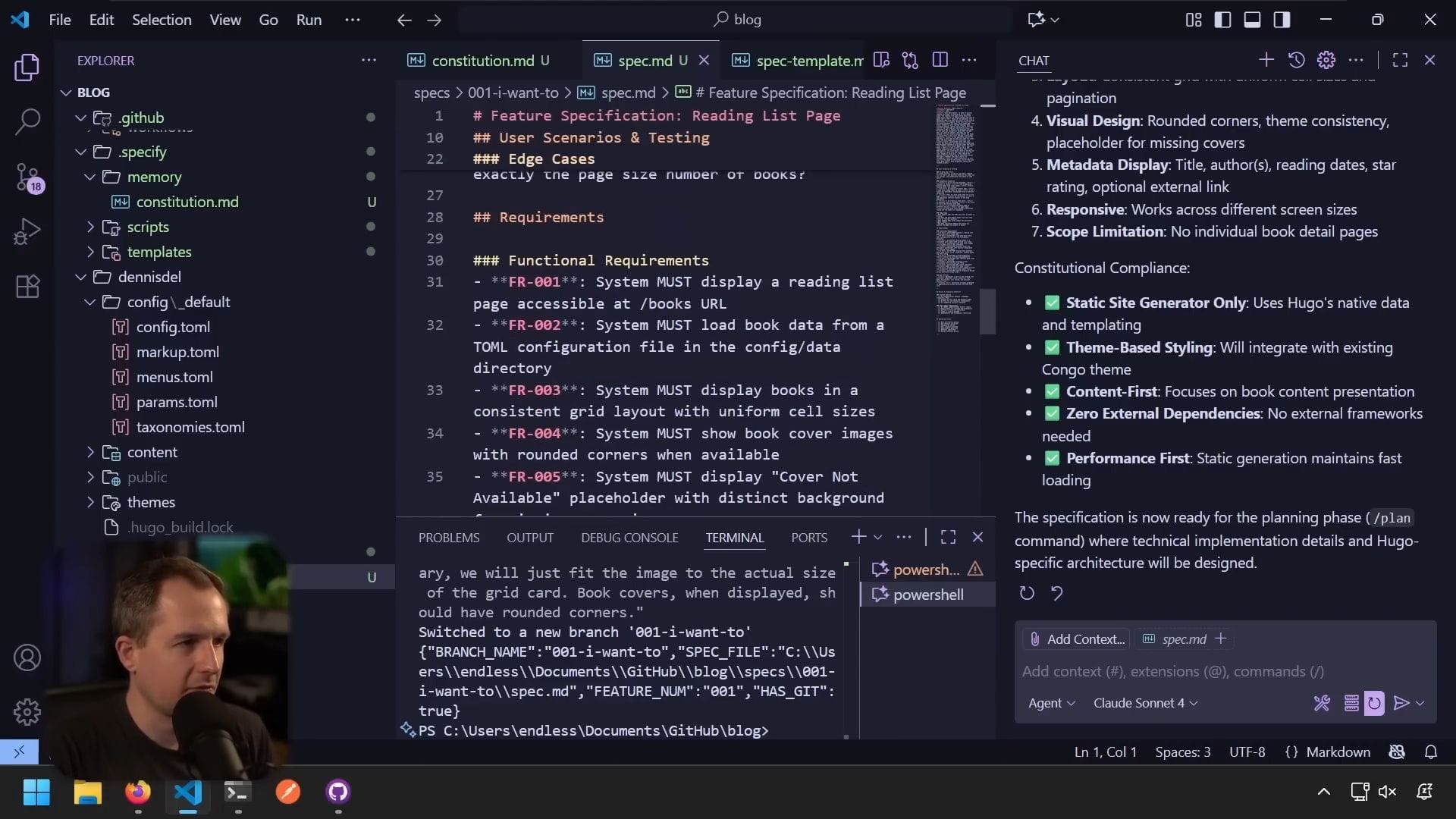
- 必須顯示可透過 /books URI 訪問的閱讀清單頁面
- 必須從資料載入書籍
- 必須在一致的網格中顯示書籍
- 書籍封面圖片要有圓角
- 書籍連結不建立個別書籍詳細頁面(我現在不需要)
- 必須處理不同螢幕尺寸的響應式設計
補充需求
我發現漏掉一個需求:要確保閱讀清單連結只顯示在頁尾。讓我加上:
閱讀清單必須列在頁尾
與其他連結一起
如 tags、work style 和 archives
這由現有的 TOML 設定控制我要引導它使用我網站的約束條件,不讓 LLM 猜測。你讓 LLM 猜測越多,它越可能偏離軌道,做出你實際上不想要的事情。
釐清規格
使用 /clarify 指令
這個指令幫助找出規格中未充分說明的項目,基於我正在建立的內容提出相關問題。
回答釐清問題
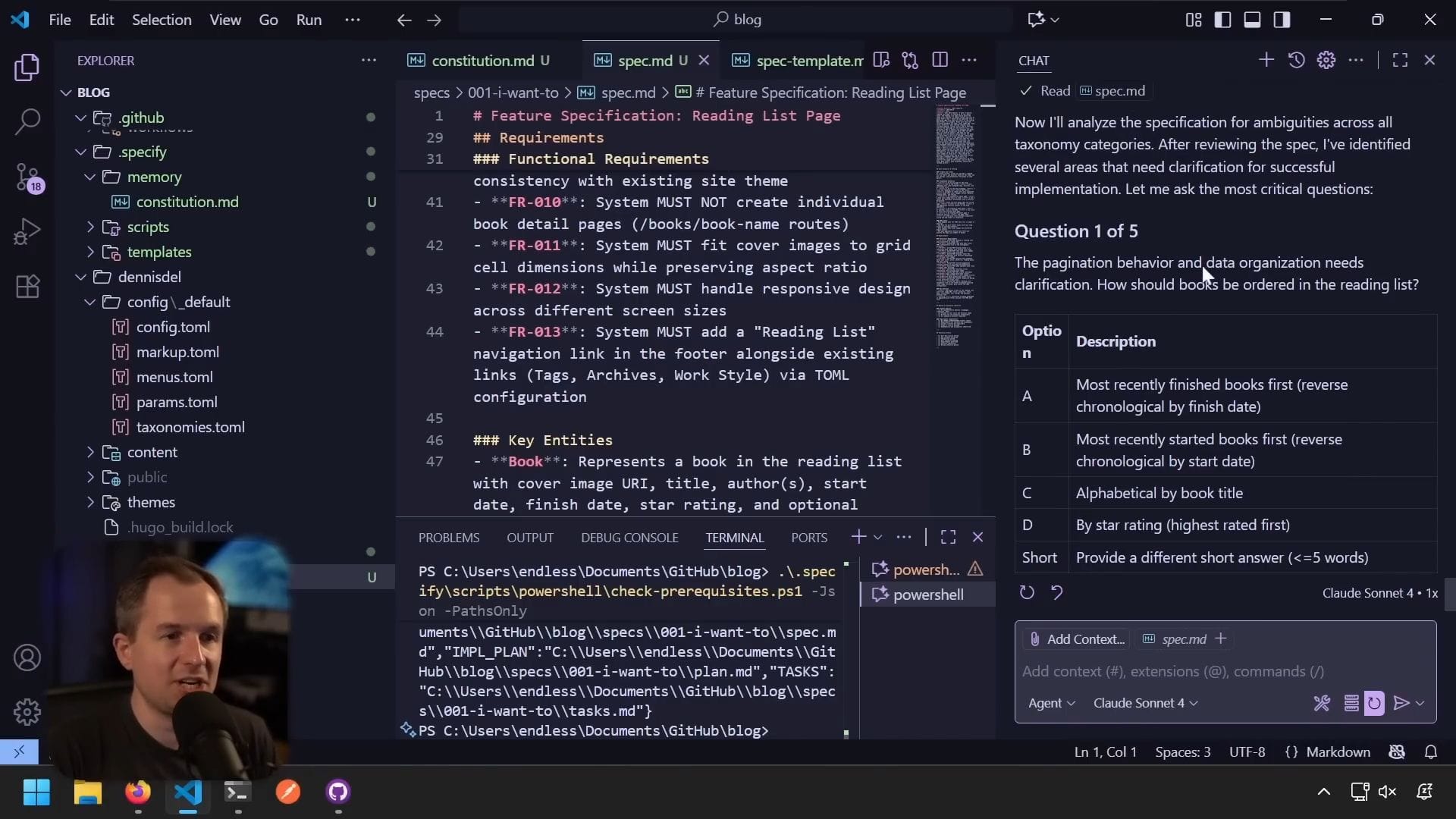
問題 1:書籍排序
- 應該如何排序?
- 答:按閱讀完成日期,最近完成的書籍在前
問題 2:分頁大小
- 每頁顯示多少本書?
- 答:20 本書(選項 C)
問題 3:評分顯示
- 如何顯示星級評分?
- 答:視覺星形圖示加數字(如 4/5)(選項 A)
問題 4:未完成書籍
- 有開始日期但沒有完成日期的書籍如何處理?
- 答:在頂部顯示為「目前閱讀中」(選項 A)
問題 5:資料驗證
- 當 TOML 檔案有無效或缺失的必要資料時該怎麼辦?
- 答:跳過無效項目,靜默顯示有效項目(選項 A)
釐清的價值
這個流程很棒,因為它讓我釐清思緒,並意識到今天咖啡喝得不夠,沒有想透這些事情。讓 AI 質疑你,不要總是你質疑 AI。
建立執行計畫
使用 /plan 指令
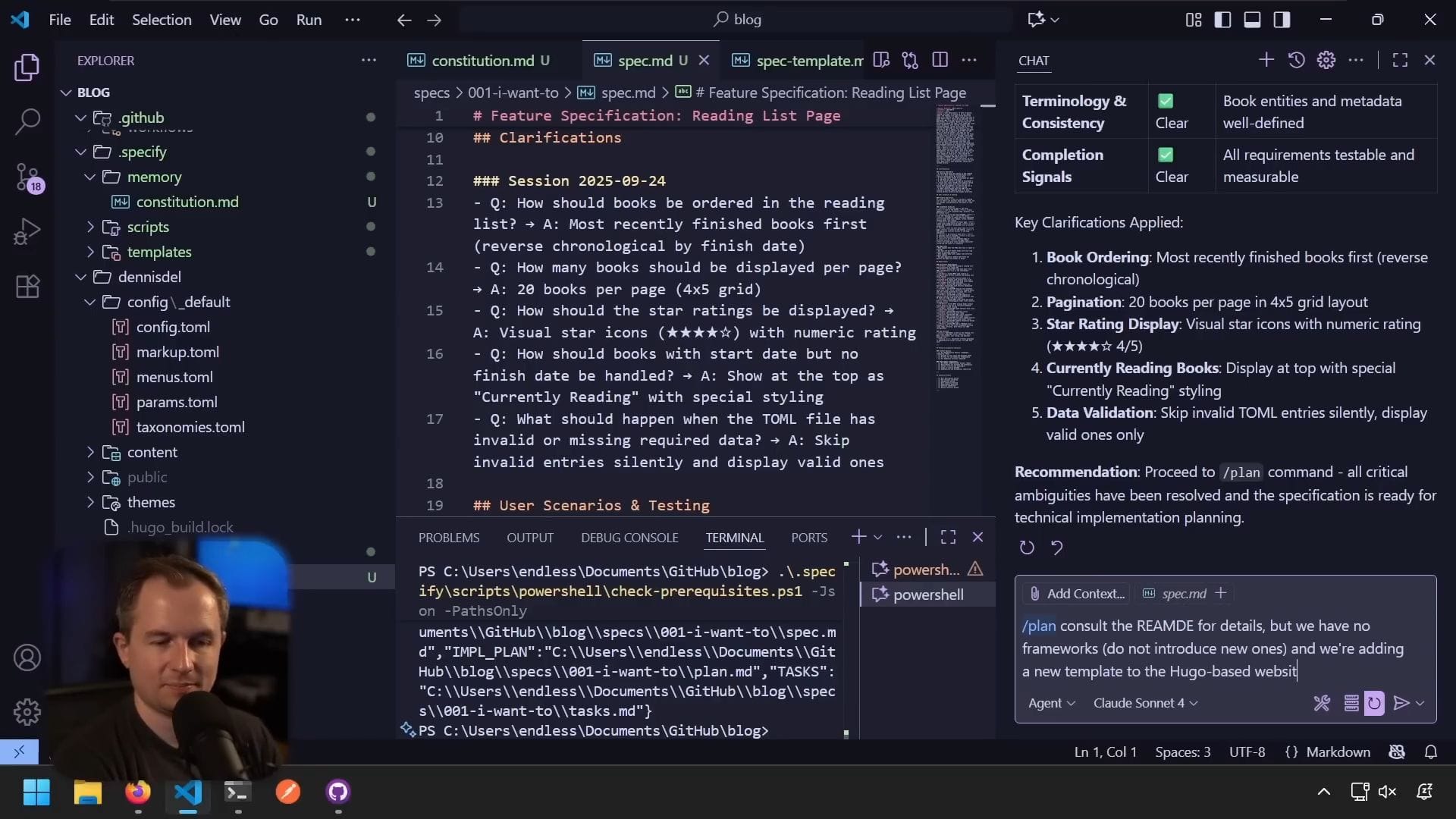
參考憲章了解細節
但我們沒有框架
不要引入新框架
正在為基於 Hugo 的網站新增模板
不會使用或撰寫任何測試我的部落格從未使用過測試,不管好壞。這不是企業應用程式,如果測試失敗或其他問題都沒關係,我們之後可以調整。
審查計畫
生成的計畫包含:
憲章檢查:
- 僅靜態網站生成器
- 基於主題的樣式
- 內容優先
- 零外部相依套件
研究內容:
- 識別了設定位置
- 理解了部落格格式
- 看到了主題、模板、佈局和靜態資料夾
它確實了解結構,這意味著它可能會生成正確的內容。
移除測試相關內容
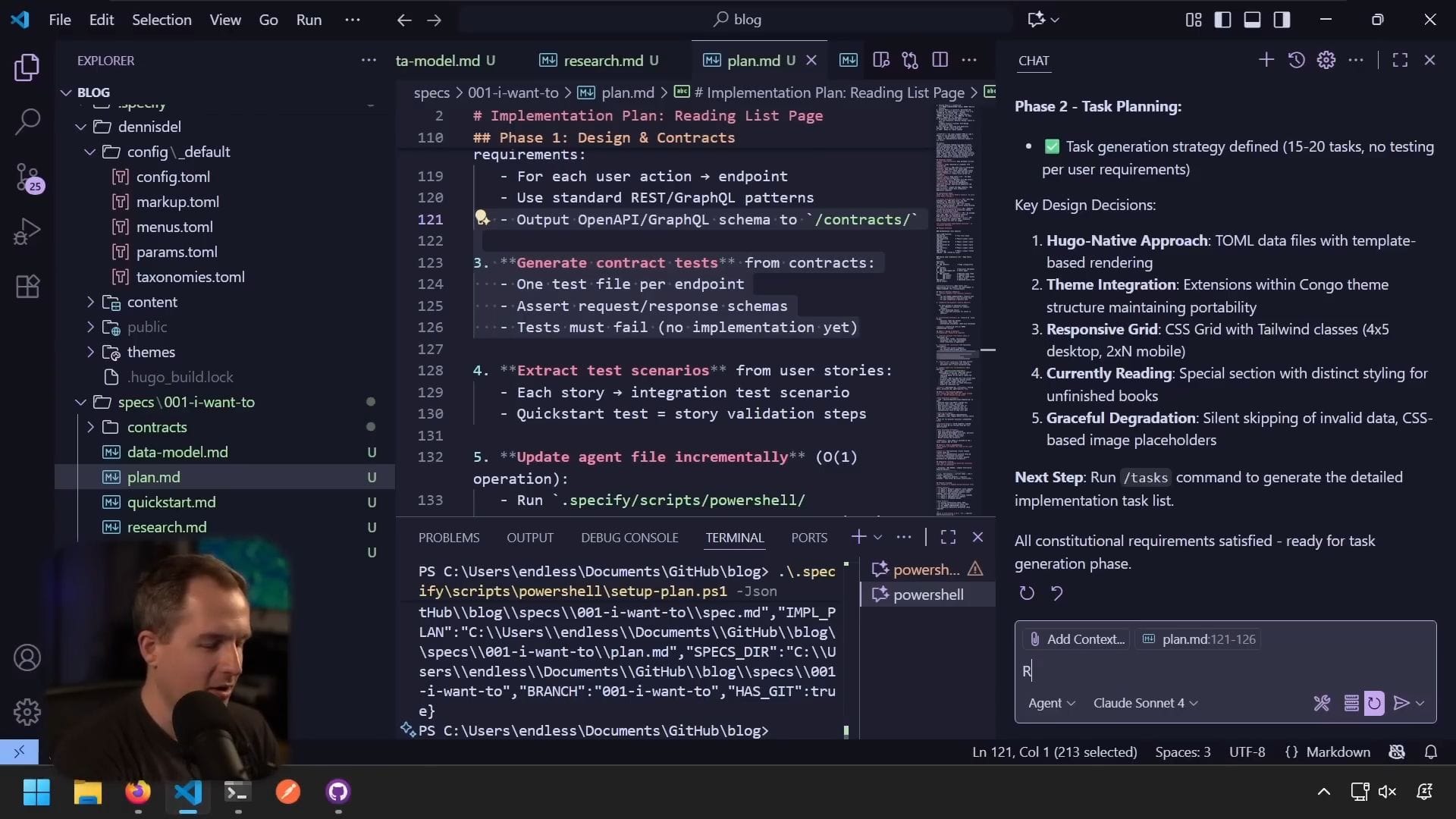
我注意到計畫中包含測試相關內容,需要移除:
從計畫中移除任何與測試相關的內容
我們不想為這個專案做測試人類仍然需要參與這個流程。
檢查契約
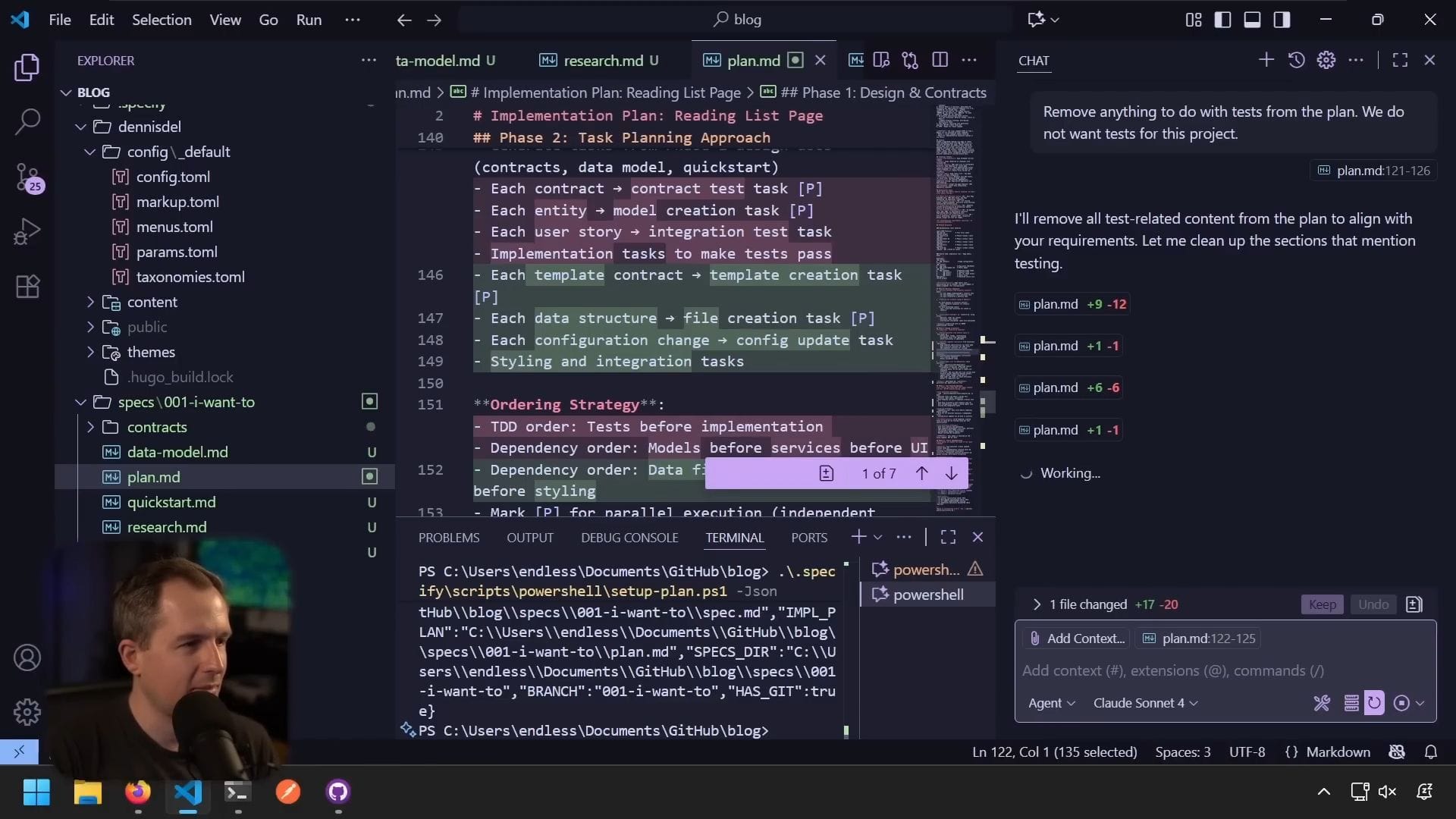
計畫建立了一些契約:
- 設定契約:理解如何引入連結
- 書籍索引:會引入新的內容頁面,類似存檔頁面
它為書籍建立了一個 index.md,類似於存檔的做法。我喜歡這個方法,因為它理解脈絡並將該脈絡套用到我正在處理的新功能上。
分解任務
使用 /task 指令
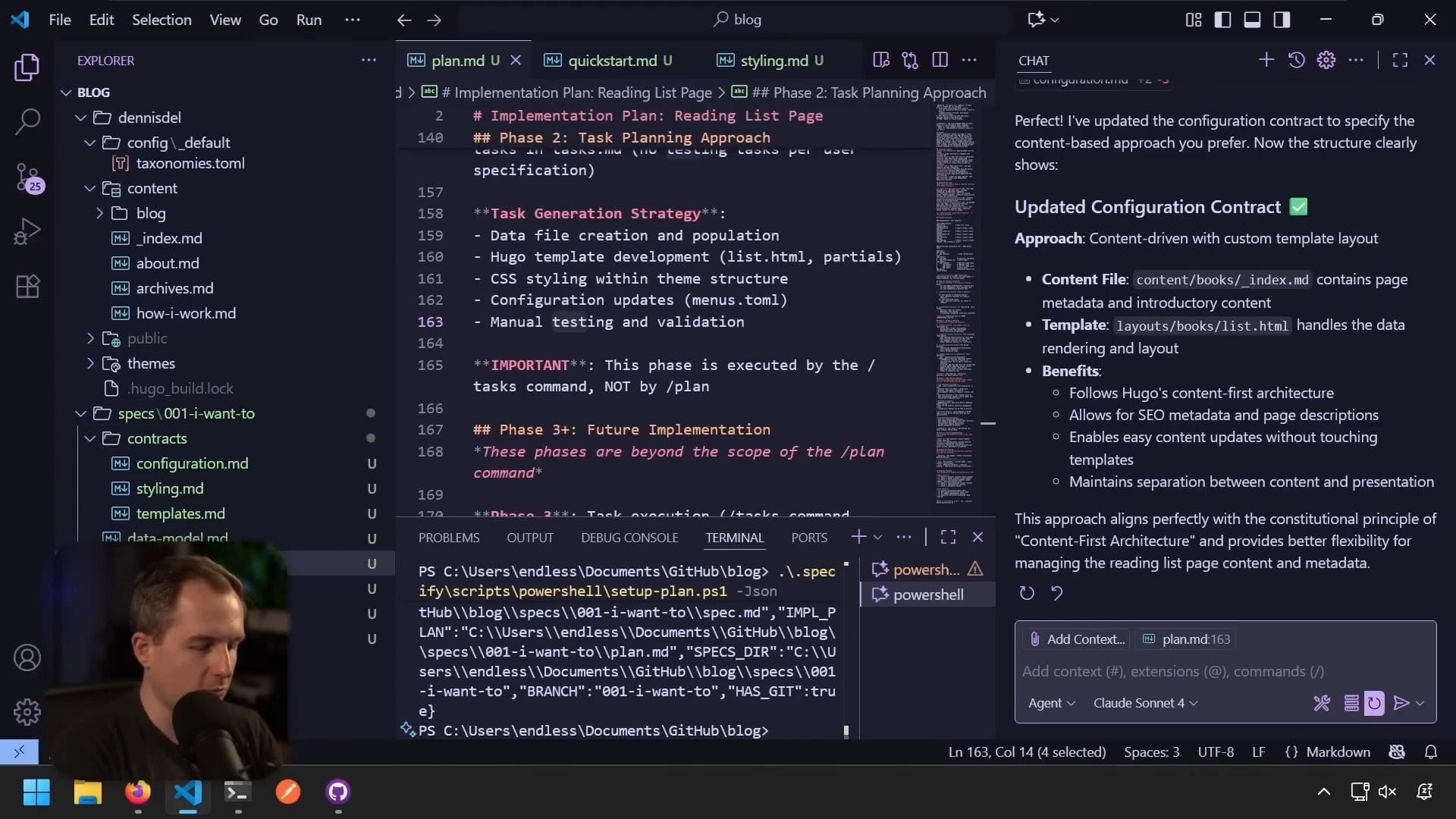
基於提供的細節,查看它需要建立什麼才能讓我們看到變更和想要的書單。
任務清單
資料設定:
- 建立資料目錄
- 建立書籍資料檔案(data/books.toml)
- 根據資料模型加入範例書籍項目
內容結構:
- 建立書籍內容目錄(content/books)
- 包含 index.md
模板和局部模板:
- 建立書籍卡片局部模板
樣式設定:
- 導航更新
- 更新頁尾選單設定
測試:
- Hugo 建立流程
- 執行 Hugo 伺服器驗證書籍頁面載入
驗證和潤色:
- 各種修補工作
這看起來很合理,是一組合理的任務。
分析規格
使用 /analyze 指令
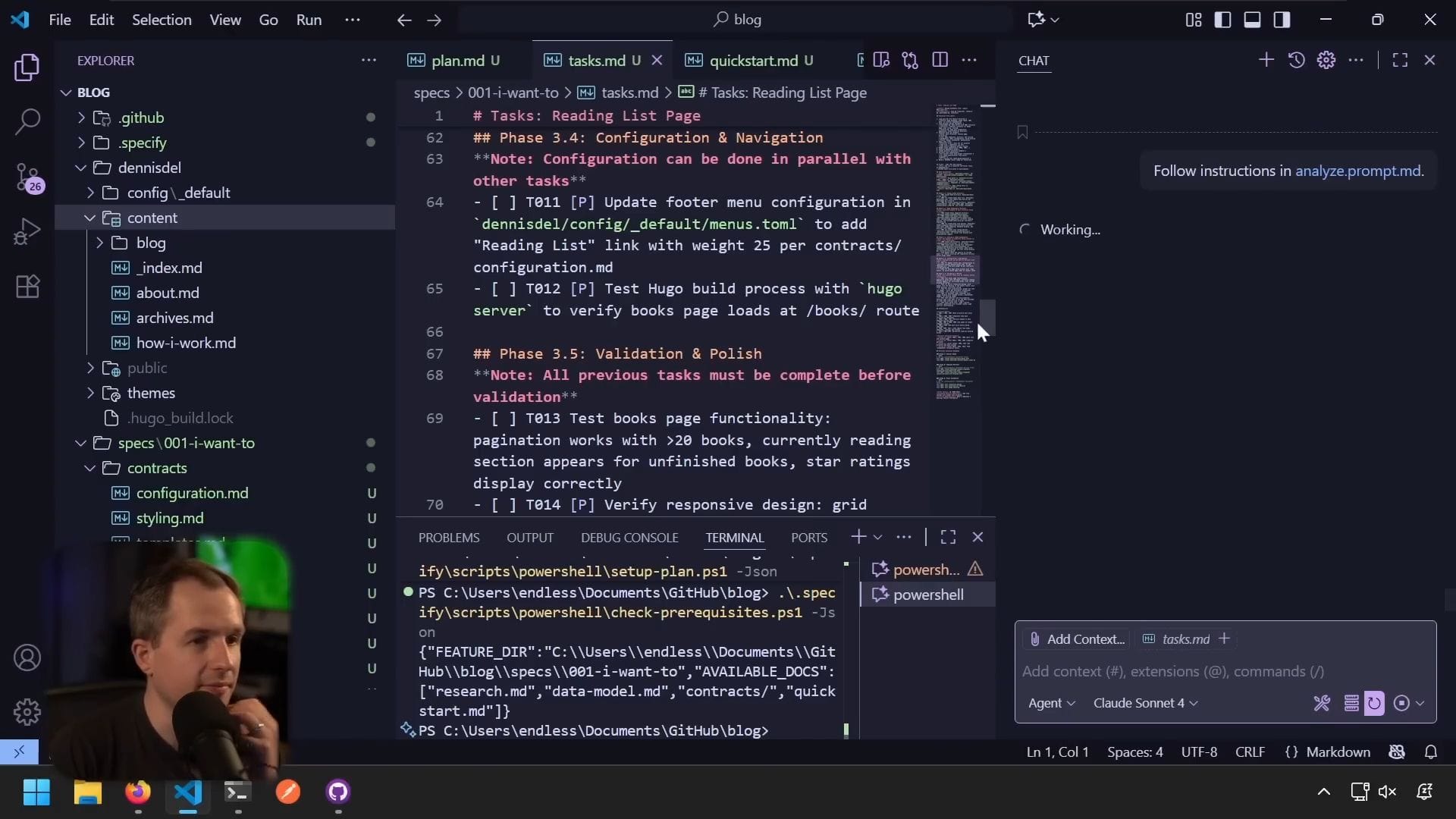
我想知道這些文件之間是否有任何憲章違規或關鍵問題。
分析結果
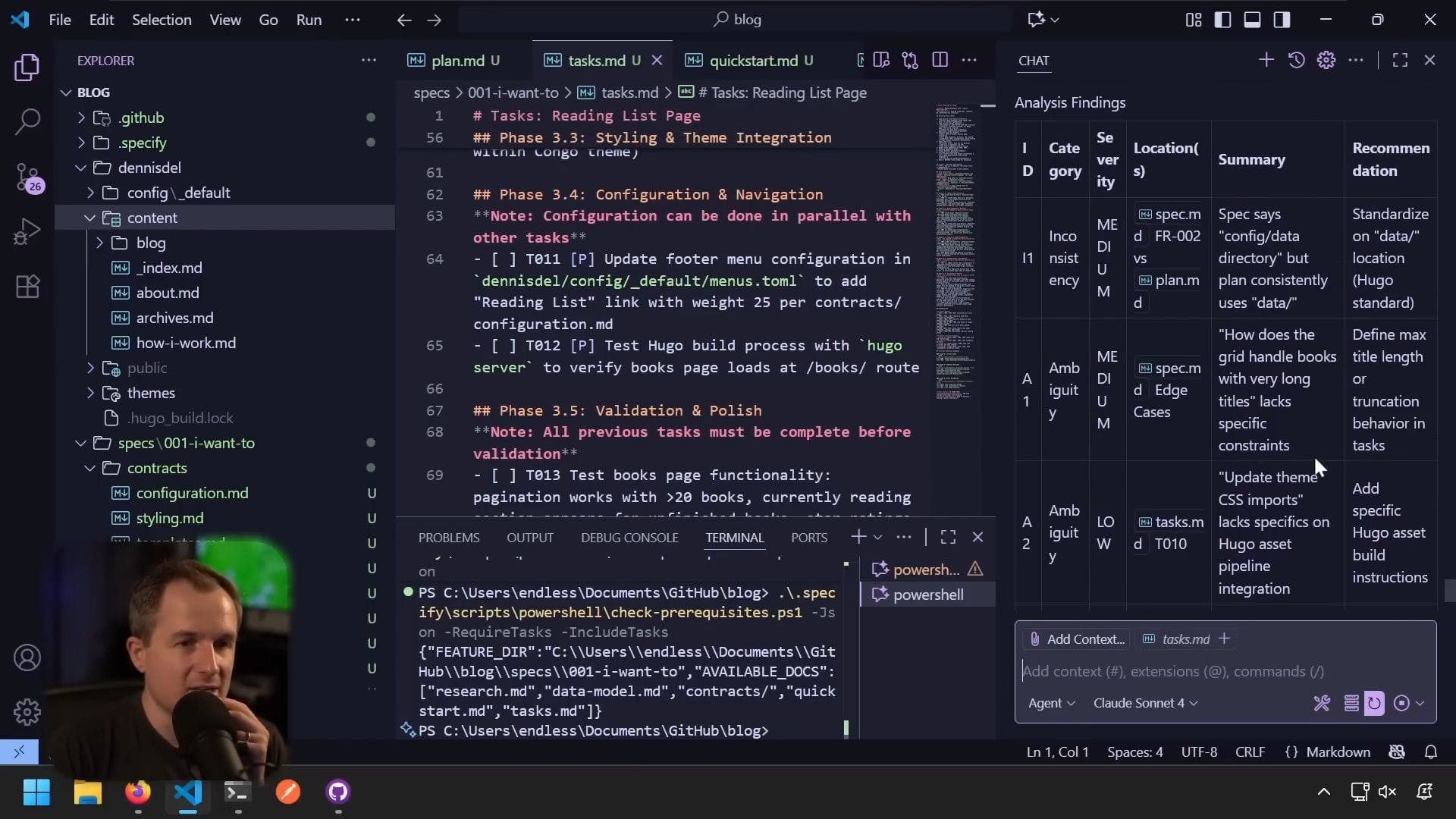
嚴重性:中等
問題 A1:
- 規格說 config 資料目錄,但計畫一致使用 data
- 建議:標準化資料位置為 data(Hugo 標準)
這是對的,它正確識別出這是 Hugo 標準。
改進建議:
- 標題長度或截斷行為
- 新增特定的 Hugo 資產建立指示
- 測試空白/缺失資料檔案
- 遵循現有主題中斷點
無憲章違規
我決定處理 A1 和 I1,其他的都還好。
更新規格
A1 和 I1,讓我們處理它們
使用標準 Hugo 慣例
對於截斷,使用標準
對於超出寬度的較長標題
更新 spec、plan 和 task我要確保這個變更被適當反映並記錄在規格中,因為當我與 AI 迭代時,我希望我做的任何決定都能實際編碼回規格中。
規格作為活文件
這對我未來意味著,如果我決定重建這個書籍頁面(因為我將網站從 Hugo 遷移到某個使用量子運算的新靜態網站生成器),我可以重複使用完全相同的規格,讓我過去的決定反映在該文件中。
我不必一次又一次從頭開始重做,因為我將規格視為一個活文件,它編碼了特定功能能力。它完全與網站的實作分離,因為我可能使用 Hugo,也可能不使用 Hugo。
實作功能
使用 /implement 指令
這是最關鍵的時刻。執行後就沒有回頭路了,無論如何我們都會有這個書籍頁面。
sonnet implement檢查變更
生成的檔案包括:
- 選單變更
- 書籍索引
- books.css
- 書單
- 書籍卡片
- 一些 CSS 檔案
- 更新的任務清單
但它沒有重建主題。這很好,因為這是迭代式的,我們會從中學習。
測試網站
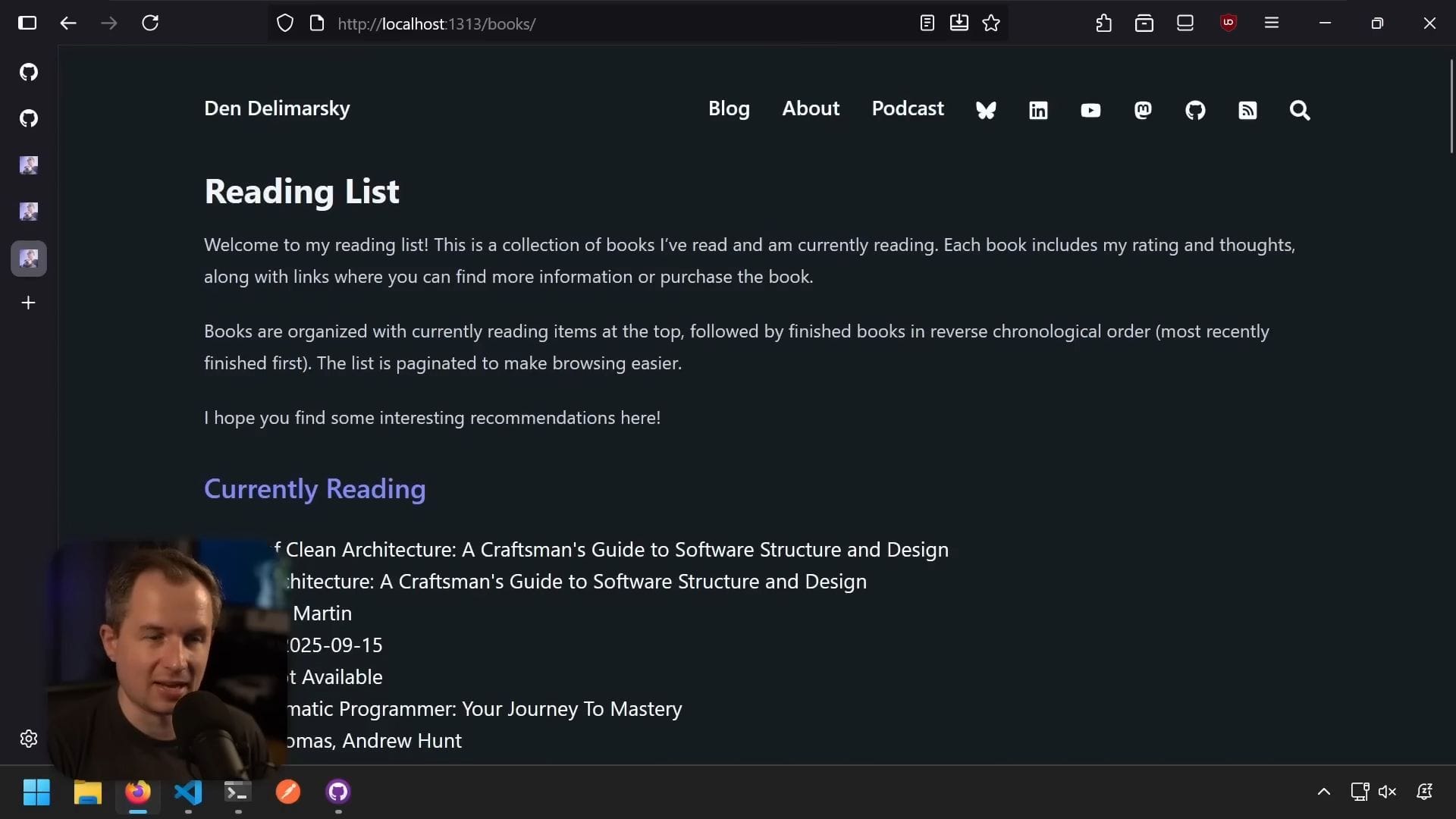
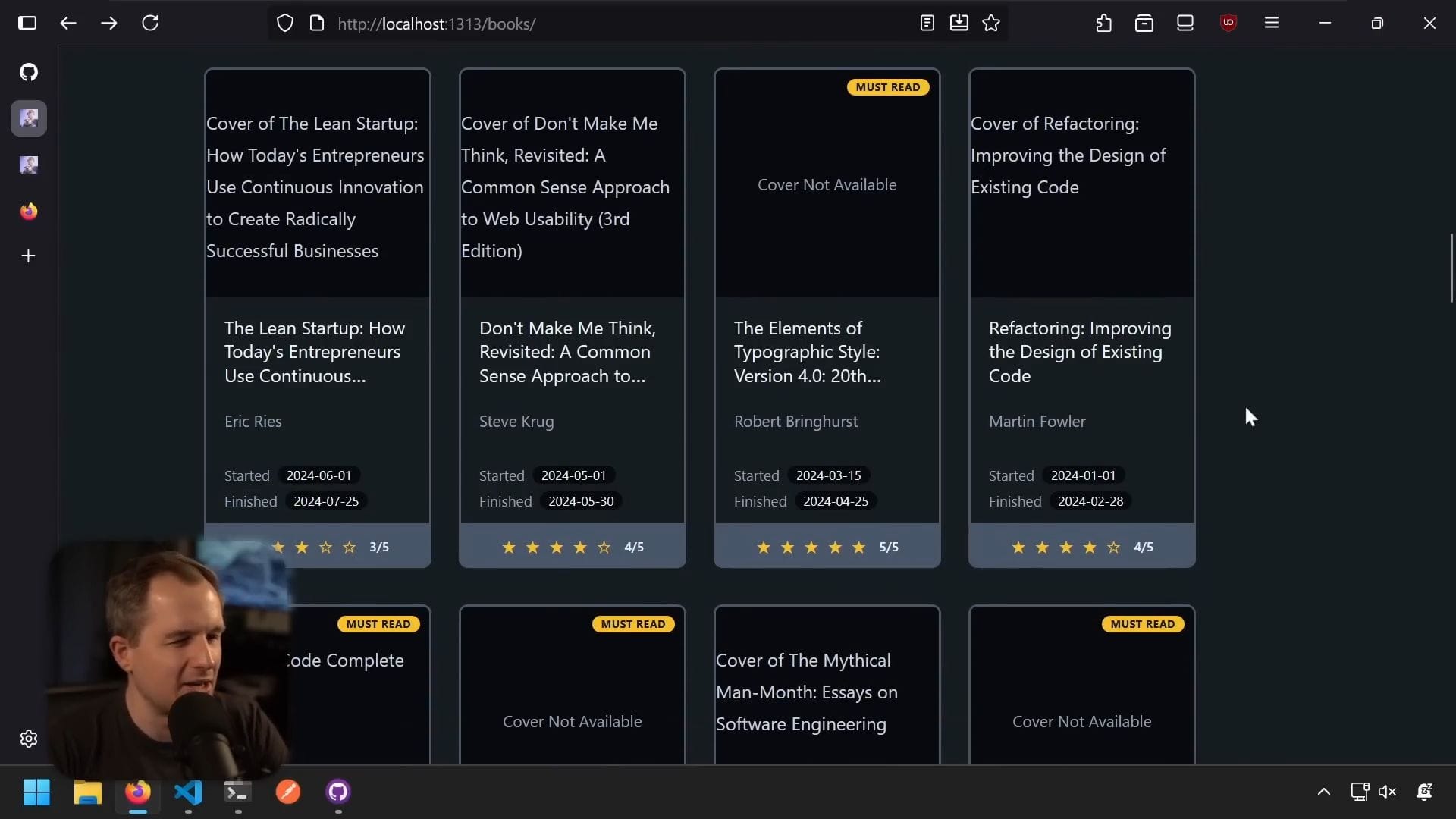
hugo server讓我們看看實際結果。打開瀏覽器,滾動到底部,看到閱讀清單連結。點擊後看到「目前閱讀中」區塊和一些書籍,但沒有看到分頁,也沒有網格。
資料模型已綁定到頁面(因為我們看到來自 books.toml 的資料),但渲染方式不是我們想要的,沒有產生網格。
迭代改進
持續迭代
我們沒有網格,所以要繼續迭代。告訴 AI 該做什麼,以符合我們想要的樣式和格式。同時確保所有這些都編碼回規格中。
在這個過程中,我在 Claude Sonnet 4 和 GPT-5 之間切換,以讓它達到理想狀態。有時你必須測試不同的模型。
最終結果
完成後,我認為效果很好。現在我有:
設計特點:
- 符合部落格設計(如預期)
- 「目前閱讀中」區塊
- 「已完成書籍」標題加計數器
- 「必讀」徽章(對我認為很棒的書)
- 漂亮的評分顯示(只有星星和計數器)
- 開始和完成日期以藥丸格式呈現
關於分頁的決定
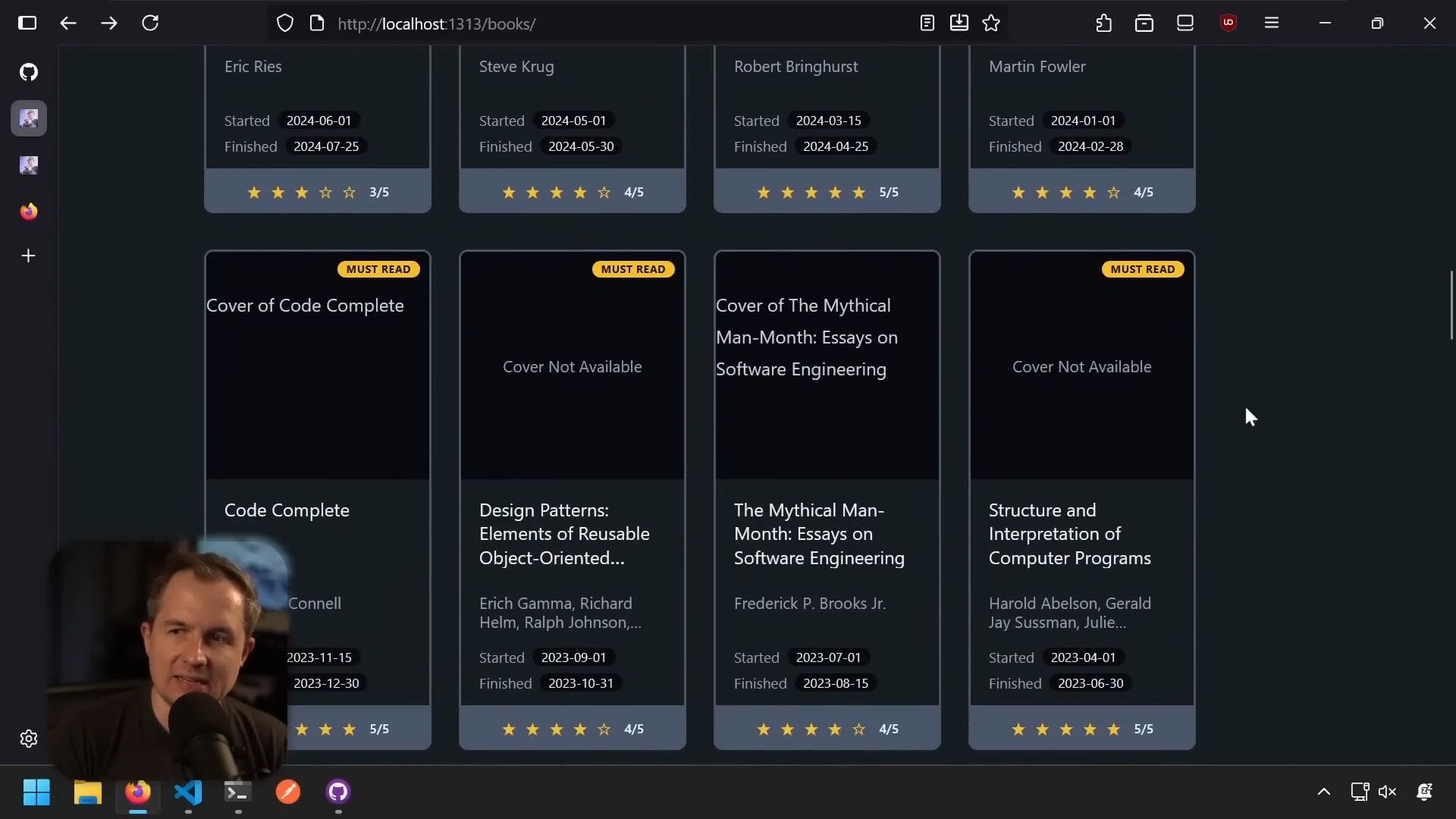
最初我在考慮分頁,但後來意識到:
- 我不想要分頁
- 我寧願在一個頁面上顯示所有內容
- 因為使用 TOML,實作分頁需要自訂 JavaScript
- 我想最小化網站上的自訂 JavaScript
- 我希望它快速、靈活,作為靜態網站運作,沒有太多 JavaScript 相依套件
所以我說,分頁也許將來再說,現在我不太在意。
成功要素
它完成了工作:
- 有了規格
- 分析了程式碼庫
- 實際讀取了 README、樣式、主題
- 將這些內容情境化並整合到規格中
- 這就是輸出結果
這個內容讓我現在能夠以對專案有意義的方式進行迭代。我對結果非常滿意。
編碼學習成果
將學習編碼回規格
基於對話
編碼學習和體驗部分
不是技術細節
到 spec.md
針對當前功能這很重要,因為你必須確保你一直在處理的學習實際上被帶回規格中。
現在我們在迭代一個功能,但也要記住可能有多個功能。所以你可能需要謹慎決定如何更新以及更新哪個規格。
審查學習內容
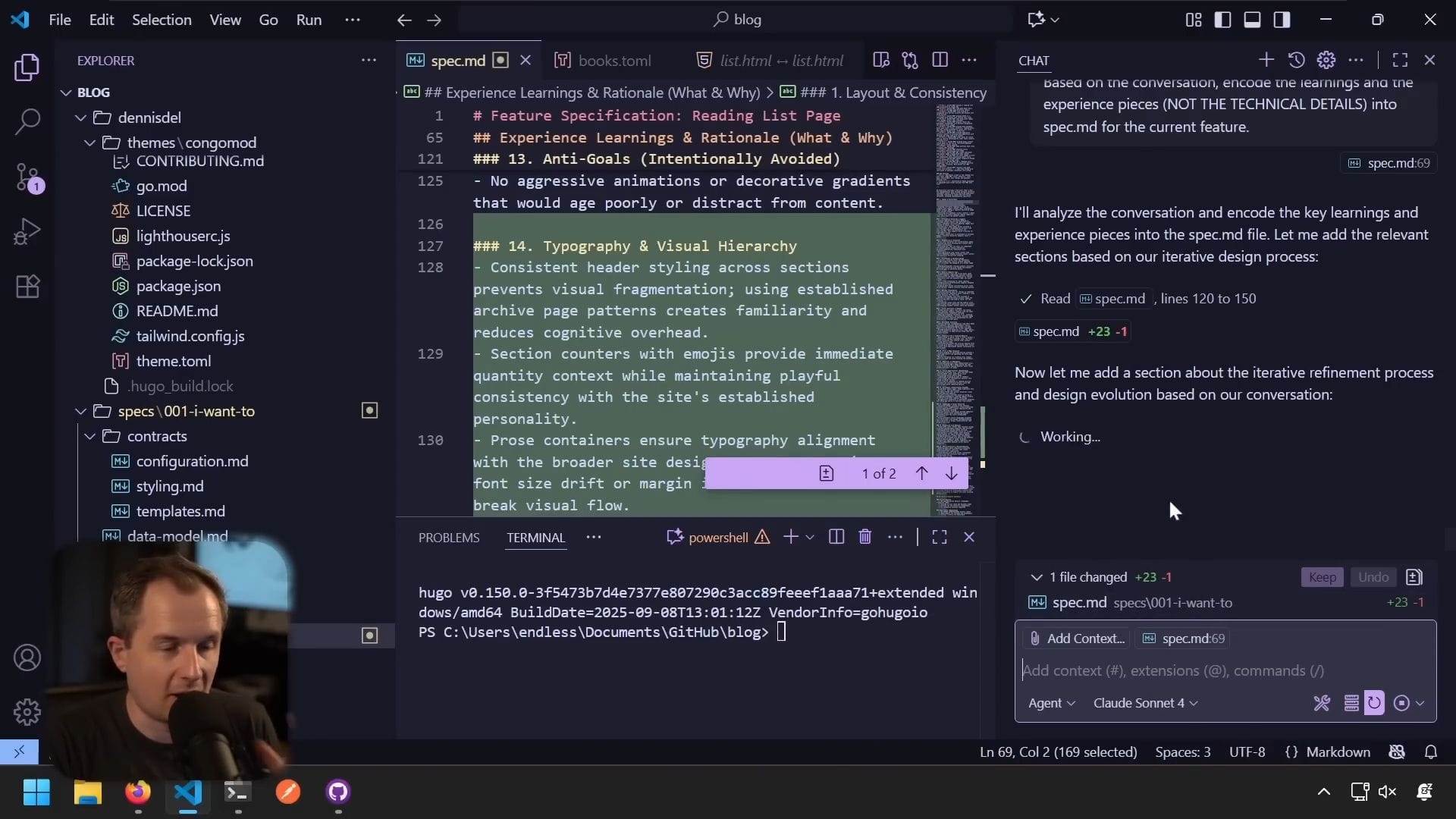
生成的學習包括:
設計演進:
- 專注於實現視覺一致性和可預測行為
- 迭代方法
- 根據經驗做假設,而非追求理論完整性
功能需求更新:
- 必須使用相同的標題樣式
- 必須實作帶表情符號指示器的區段計數器
- 必須使用固定寬度的卡片尺寸
- 媒體查詢要正確,因為卡片一直在跳動
學習的重要性
我們從這次經驗中學到的需要編碼回規格中。如果我刪除現有的書籍體驗程式碼並重新建立,LLM 應該能更容易地重新建立我想要的確切體驗,因為我不需要來回重複所有這些對話。
結論
這就是如何為現有程式碼專案新增功能。我希望這有幫助。我很好奇你如何在專案上迭代,什麼有效,什麼無效。
我們期待大量回饋。在評論中留言、前往 GitHub、或以任何方式聯繫我提供回饋,我們很樂意為你改進這個工具。
請讓我們知道如何讓 SpecKit 變得更好。下次見!